
GreengrassからIoT coreに受け取ったデータを、Lambdaで『その4』で作成したDynamoDBのテーブルに書込み、時間範囲指定クエリで読み出してみます。
Lambda
LambdaはEC2のような仮想サーバーなしでプログラムを実行してくれます。 LambdaをDeployすると、指定したトリガでLambda Functionの中のlambda_handler()関数が呼び出され実行されます。 Lambda Functionの中で、サポートされている言語は、Python、NodeJS、Java、C#、F#、Powershell、Ruby。 今回はPythonを使います。
Lambda Function作成
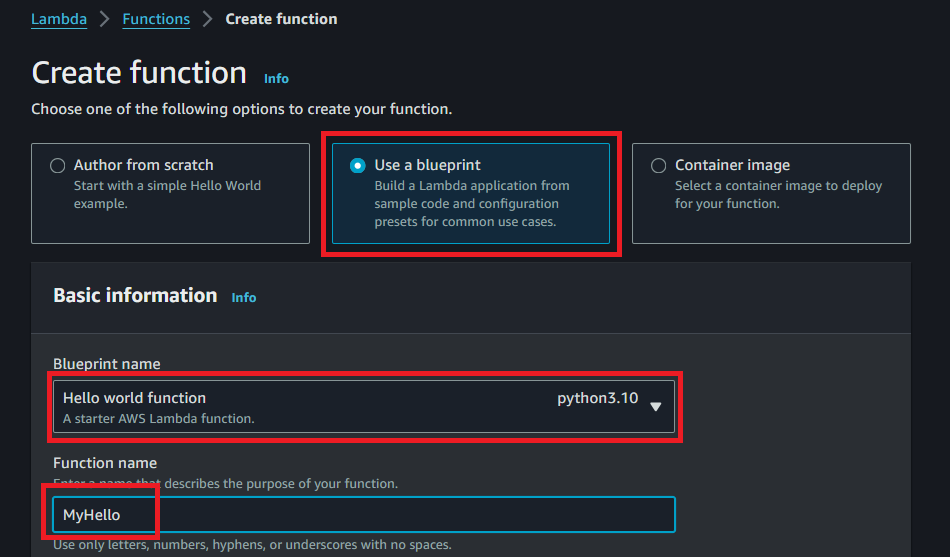
- 『Lambda』画面に移動
- 『Create function』
- 『Use a blueprint』を選択し
- Blueprint nameで『Hello world function python3.10』を選択し
- Function nameを『MyHello』入力し
- 『Create a new role with basic Lambda permissions』のまま
- 画面下にスクロールダウンして『Create function』をクリック
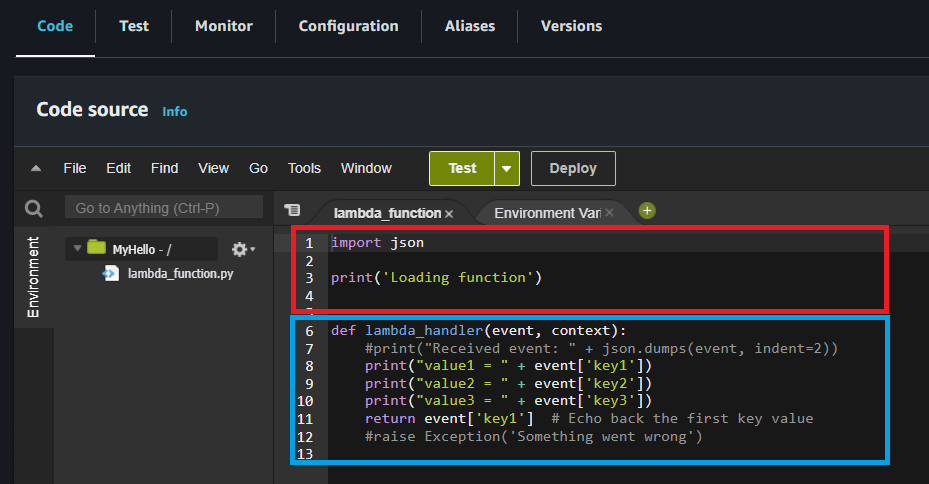
- MyHello画面が開きます
- 赤枠と青枠全体がLambda FunctionのMyHelloです
- Lambda Function内の赤枠部分はその上のDeployを押した時に毎回1回だけ実行されます。
- その後はLambda Function内に青枠のdef lambda_handler()がありますが、この部分がイベントソースによって呼び出されます。 今回は、IoT Coreが受信した時に呼び出すようにTriggerを設定していきます。
- 時々、イベントでLambda関数呼び出しと書かれている記事がありますが、正確にはDeployでLambda Function(関数)が実行され、イベントTriggerでLambda Function内のlambda_handler関数が呼び出されるという事です。
- returnの値は呼び出されたイベントソースに送られる。 例えばAPI Gatewayから呼び出された場合、API Gatewayに値を返します。
Permission設定
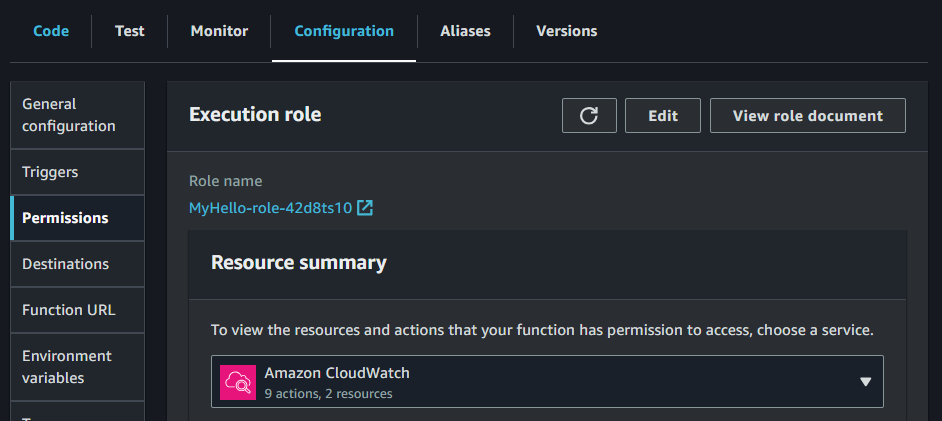
- 上部の『Configuration』タブ~左の『Permission』タブをクリック
- これで新しいroleが出来ています。
- このRoleをクリックすると、『AWSLambdaBasicExecutionRole…』が繋がっています。
- 更に『AWSLambdaBasicExecutionRole…』をクリックするとCloudWatch Log CreateLogGroup, CreateLogStream, PutLogEventsの3つのpermissionが入っています。
- しかしLambdaがIoTやDynamoDBにアクセスする時に権限(permission)が必要になります。
- MyHello-role…をクリックして『Add Permission』~『Attach Policies』で権限追加します。
- 私は今回は面倒臭いので『dynamo』と『Iot』で検索して『AmazonDynamoDBFUllAccess』と『AWSIoTFullAccess』を追加しています。
- 必要最低限を追加するには、Lambdaを実行してpermissionエラーとなった権限だけのpolicyを追加したら強固なセキュリティになります。
Trigger作成
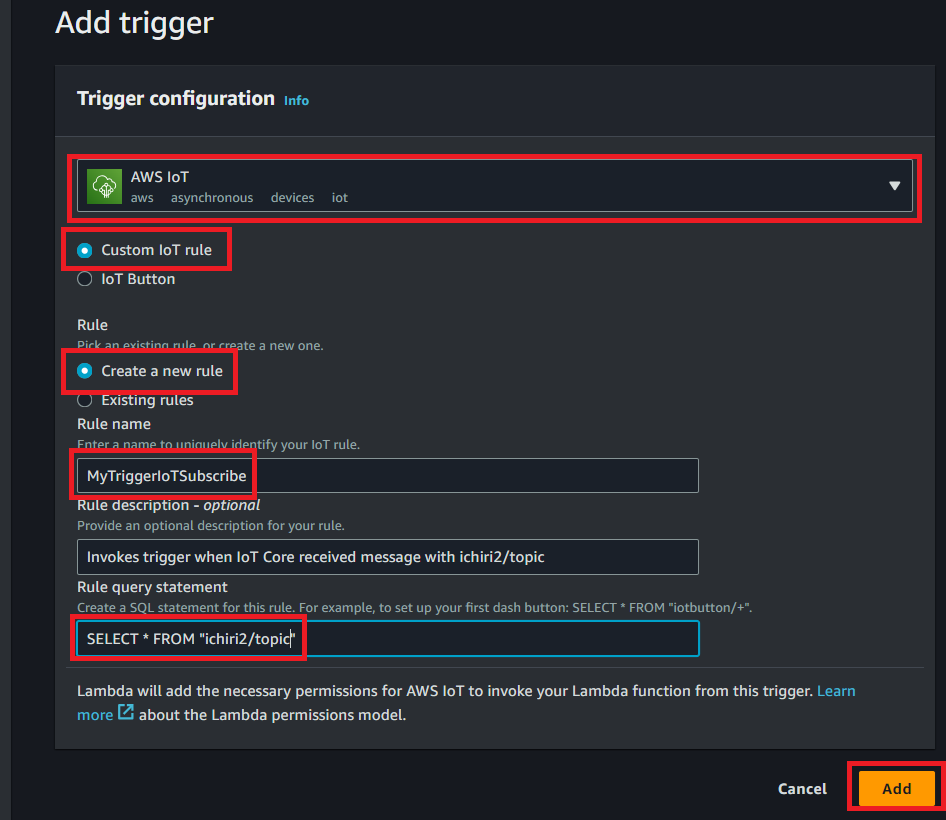
- 『Add trigger』をクリック
- 『AWS IoT』を選択
- 『Custom IoT rule』を選択
- 『Create a new rule』を選択
- Rule nameを入力『MyTriggerIoTSubscribe』
- Rule descriptionは入力してもしなくても構いません。
- Rule query statementに『SELECT * FROM “ichiri2/topic”』と入力して『Add』
- このRuleは『IoT』~『Message routing』~『Rules』から確認、変更が出来ます。
- Lambda Function MyHelloを以下の様に変更します。
- 『Lambda』画面~『Functions』~『MyHello』選択~『Code』タブ選択するとコードが表示されるので、張り付けます。
- 『Deploy』をクリック
- 『その3』で作ったcom.example.Publishコンポーネントをrestartします。
- com.example.Publishコンポーネントを起動するデバイスのコンソールから『sudo greengrass-cli component restart –names “com.example.Publish”』
- すると”ichiri2/topic”トピックで5回Publishするので、IoT Coreが受信して、Triggerが起動してMyHelloのlambda_handler()が5回呼び出されます。
import json
print('Loading function')
def lambda_handler(event, context):
print('**********EVENT****:',event)
print('**********CONTXET**:',context)
#print("Received event: " + json.dumps(event, indent=2))
print("value1 = " + event['key1'])
print("value2 = " + event['key2'])
print("value3 = " + event['key3'])
print("counter = " + event['counter'])
return event['counter'] # Echo back the first key value
#raise Exception('Something went wrong')
CloudWatchで確認
Lambda Functionを作ると自動的にそのLambda Function用のLog groupがCloudWatchに生成されてprint文等の情報を見る事が出来デバッグに使用できます。 既にMyHelloのlambda_handle()が5回呼び出されているので、5回分のLogが残っているはずなので確認します。
- 『CloudWatch』画面に移動
- 『Logs』~『Log groups』~『aws/lambda/MyHello』をクリック
- 画面の下の方にLog streamsが表示されるので一番新しLog streamをクリックします
- 一番下が一番新しいログです。
- 一番上に移動します。
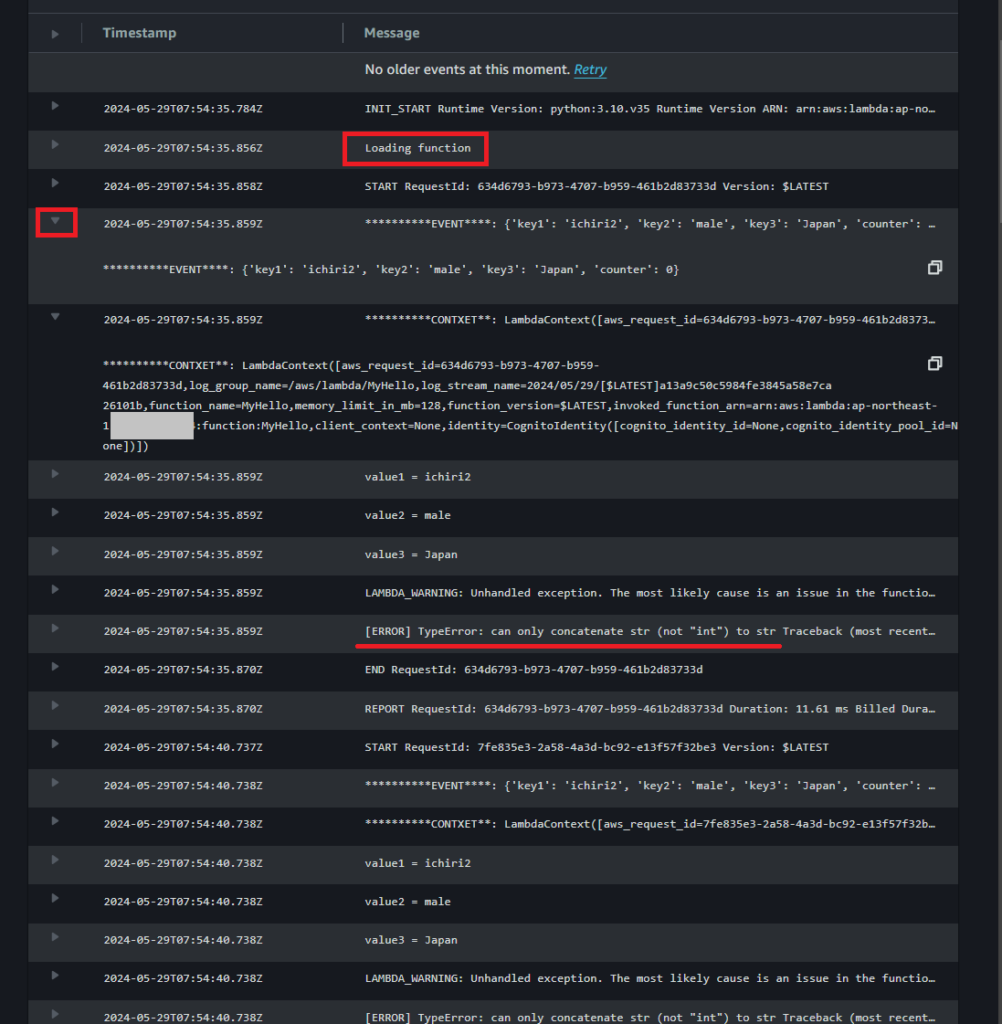
- 『Loading function』とありますがこれはdef lambda_handler()の外に記述されているので最初の一度しか呼び出されません。
- STARTからREPORTまでがlambda_handler()の結果です。
- 左の▼をクリックしてEVENTを確認します。 lambda_handler()の引数のeventの中身が見えます。 eventがpayloadです。 contextはMyHelloの情報です。
- その下のvalue1=ichiri2にはprint文の結果が表示されています。
- しかしcounter部分はprintされておらず[ERROR]となっています。 これはcounterの値がintの数値であるのに、文字列”counter =”と『+』で結合しようとしたからです。 このようにPythonのエラーTraceback情報が表示されます。
- 以下の様にstr()を付けてint型をstr型にキャストするよう修正して、
- MyHelloを『Deploy』して、
- 再度com.example.Publishを再起動(restart)して、
- CloudWatchのLog streamを確認したらcounter = 0とちゃんと表示されました。
print("counter = " + str(event['counter']))
LambdaでDynamoDBに読み書み
- さてそれでは『その4』で作成したテーブルに読み書きします
MyHelloのDynamoDBアクセス権限設定
Lambda FunctionのMyHello作成時CloudWatchへのアクセス権限は自動的に設定されました。 しかしDynamoDBへのアクセス権限はまだ設定していないので、これから設定します。
- 『Lambda』画面に移動
- 『Functions』~『MyHello』をクリック
- 『Configugation』タブをクリックして
- Roleをクリック。 私の場合、MyHello-role-で始まるRole nameです。
- *余談ですが、GreengrassのThingにはRoleは直接Attachできず、RoleをRoleAliasにして更にPolicyに付加してThingのCertificateにAttachしました。 この辺はサービスによってやり方が異なるのは混乱しますね。
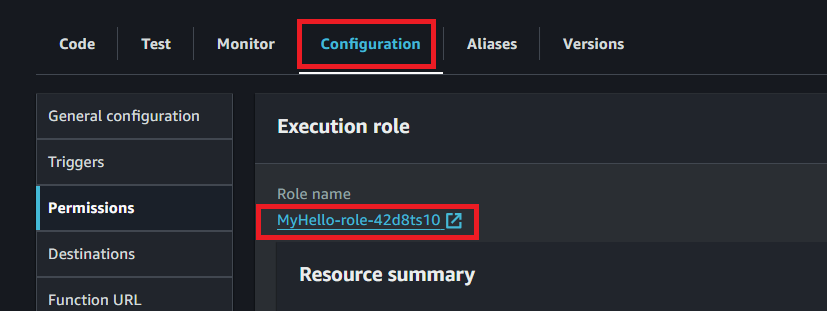
- 『Permission』(権限)タブ選択
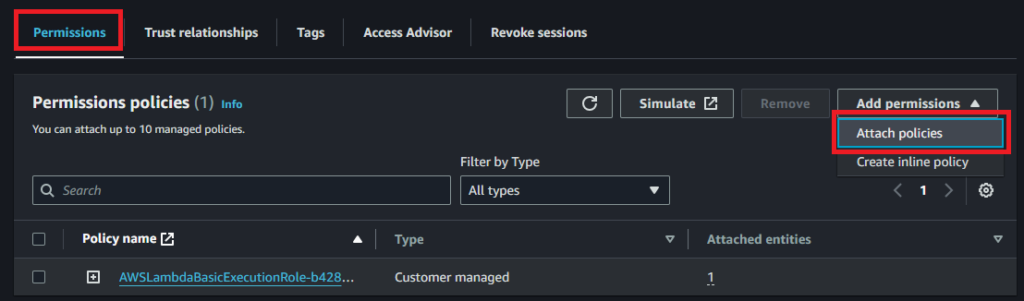
- 『Add permission』(権限追加)をクリックして『Attach policies』クリック
- AWSLambdaBasicExecutionRole-…にDynamoDBアクセス権限を追加します。
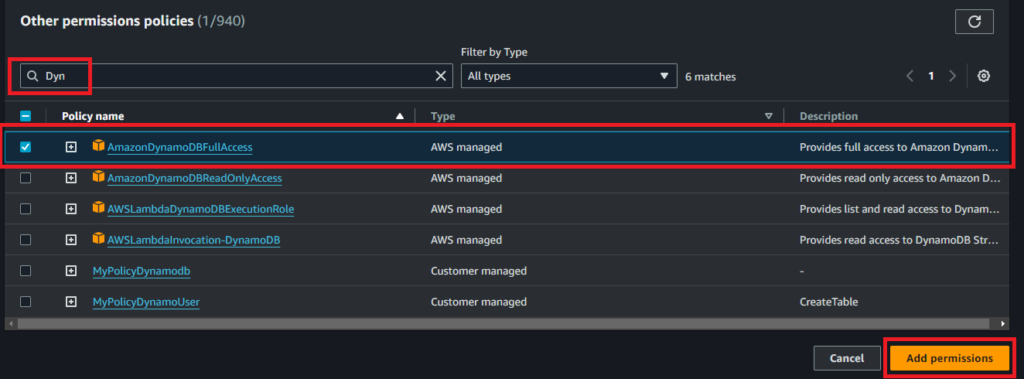
- 検索部分にDynと入力
- 『AmazonDynamoDBFullAccess』の左にチェックを入れて
- 『Add permission』
- 以下Lambda Function MyHelloはIoT Coreで『ichiir2/topic』と言うトピックに受信した時にトリガがかかり実行されます
- まずDynamoDBへアクセスのオブジェクトを生成します。
- 次にテーブルへのアクセスののオブジェクトを生成します。これはlambda_handler()(Lambda funtion)の外で一度だけ生成しておきます。 関数ないで生成しても関数終了後に破棄されるので問題ないと思いますが、何度も呼び出されるときに、生成~破棄をする処理時間が無駄になると可能性が高い
- タイムスタンプは文字列で入力。 今回はISO8601形式(*末尾Zなし)で入力していますが、実使用では、Epoch UTC形式でint型で入れた方が範囲指定する際の比較速度が速いのではと思います。
- MyHelloに以下のコードにコピペで置き換えます。
- DynamoDBのitemに入れる情報は
- Partition Key: Partitionkey名はDynamoDB Table作成時deviceIDとしたのでdeviceIDをKey名とします。
- Sort Key: Sort Key名もtimestampとしたのでtimestampをkey名とします。
- 属性(Attribute)
- ここでは参考としてURL形式とJSON形式と配列形式にしています。
- 属性名は何でも構いませんが、属性名を変更すると属性名の数だけ列(カラム)が増えて処理速度が落ちるので出来るだけ少ない数にする事がお勧めです。 ここではUrl、attr1とstatusの3つの属性名でDynamoDB Tableに3列追加されます。
- attr1でevent[“key1”]やevent[“counter”]とするとeventに入ってくるAWS IoT MQTT payloadの値を入れています。
- queryする際、ISO8601形式で時間指定しています。
- 取り出す値、時間範囲内の全てなのでは最後に入れた値だけ表示するようにしています。
import json
import boto3
from boto3.dynamodb.conditions import Key
import time,datetime
print('*******Loading MyHello')
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('gm1_table')
def lambda_handler(event, context):
print('**********EVENT****:',event)
# current_time_ms=str(datetime.datetime.fromtimestamp(int(time.time()*1000))) # msの場合
current_time=str(datetime.datetime.fromtimestamp(time.time())) # 分解能はnsを使用
device_id="ichiri.sensor.0001"
ret = table.put_item(
Item={
"deviceID":device_id,
"timestamp":current_time,
"Url": "https://www.hinatazaka46.com/s/official/diary/detail/30775?ima=0000&cd=member",
"attr1": { "name":event["key1"],
"Number":event["counter"]
},
"status": [1,"2",device_id,"b",event["counter"]]
}
)
START_TIMESTAMP="2024-05-29 02:30:35.527212"
END_TIMESTAMP="2024-06-29 02:30:47.530207"
option = {
'KeyConditionExpression':
Key('deviceID').eq(device_id) & \
Key('timestamp').between(START_TIMESTAMP, END_TIMESTAMP)
}
res = table.query(**option)
last_item=None
i=0
for item in res['Items']:
last_item=item
i+=1
print("Query result:items:"+str(i))
print(str(last_item))
return
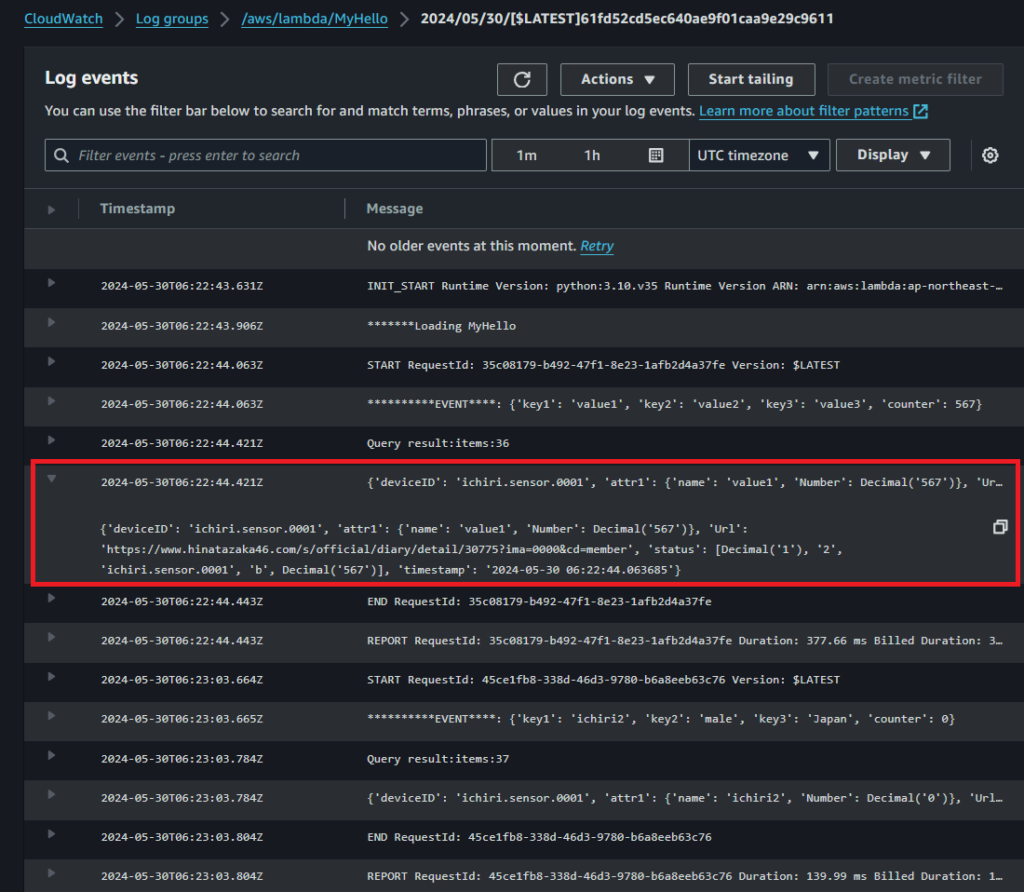
- 『CloudWatch』に移動
- 『Log groups』~『aws/lambda/MyHello』をクリック
- 一番新しいログをクリック(初期設定では一番上)
- queryで読み出せているので、DynamoDBに書き込めているという事です。
- 時間範囲指定でqueryして取り出したitemsも36itemあり、全てを表示するのは大変なので最新だけ表示しています。 時間範囲指定幅が短いと何回も書き直さないといけないのである程度の幅を持たせています。 テスト時本来は、実行した時の10秒前くらいからのqueryにしたらいいと思います。
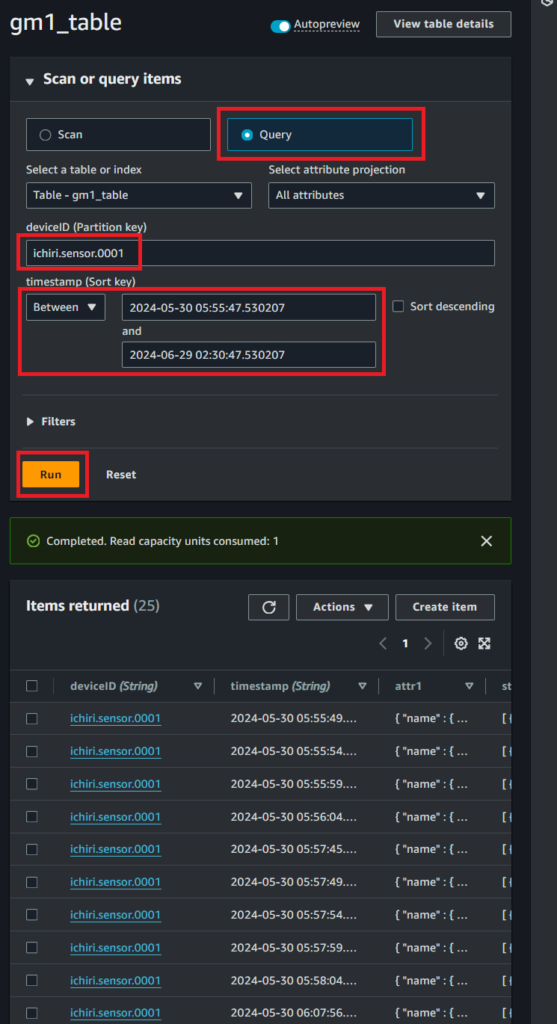
DynamoDBコンソールで確認
- 『DynamoDB』画面に移動
- 『Explore items』~『gm1_table』(作成したテーブル)を選択
- 以下の画面では『Scan』を選ぶとテーブルの全ての値を読み出すので、テーブル内の容量が多い場合は課金されてしまう可能性が上がります。
- なので『Query』を選択して、Partition Key(deviceID)とSort Key(timestamp)を入れて『Run』(実行)します。
- 時間は『2024-05-30 05』などus単位でなくても呼び出してくれます。
形式
上記のプログラムでJSON形式(MAP)や配列形式(List)の値を属性(項目:item)に入れる(put)する場合、実際のDynamoDBに入ると、JSONはList内の値に関しては”S” (String)や”N”(Number)が自動的に入ってきます。 URLを入れた単純な文字列の場合はそうなりません。
{ "name" : { "S" : "ichiri2" }, "Number" : { "N" : "0" } }
[ { "N" : "1" }, { "S" : "2" }, { "S" : "ichiri.sensor.0001" }, { "S" : "b" }, { "N" : "4" } ]

 www.hinatazaka46.com
www.hinatazaka46.com
しかし、DynamoDBからquery()で値を取り出すと、item(1行)全てを{}で括ったJSON形式ににたっ形式で入ってきます。 Pythonの場合は<class ‘dict’>で取り出せるので便利。 そして”S”や”N”と言った型は無くなっています。 ただし、数値のところはDecimal(‘1’)などの様になります。
{'deviceID': 'ichiri.sensor.0001', 'attr1': {'name': 'ichiri2', 'Number': Decimal('1')}, 'Url': 'https://www.hinatazaka46.com/s/official/diary/detail/30775?ima=0000&cd=member', 'status': [Decimal('1'), '2', 'ichiri.sensor.0001', 'b', Decimal('1')], 'timestamp': '2024-05-30 06:23:08.683769'}
やっとここまで来ました。 これでおしまい
(参考) 強い整合性のある読出し方法
//get_itemの場合
try:
itemdata = table.get_item(
Key={
"userid" : "U00001",
"updatedatetime" : "2018-04-08 09:01:00"
},
ConsistentRead=True
)
except Exception as e:
logging.error("type : %s", type(e))
logging.error(e)
//queryの場合
try:
response = table.query(
KeyConditionExpression=Key('partition_key_name').eq('partition_key_value') & \
Key('sort_key_name').between(START_TIMESTAMP, END_TIMESTAMP),
ConsistentRead=True
)
except Exception as e:
logging.error("type : %s", type(e))
logging.error(e)

コメント