
今回は普通のPostgreSQLのDBを作る手順です。
未完成ですが、自分の参考のために公開しています。
VPC作成
AuroraDBはVPCやsubnetが必要。
default VPCは、セキュリティ設定などが緩く、本番では良くないので、VPCを作成してみます。(Knowlegebaseを作った時に、ここを参考にさせていただきました。 BedrockナレッジベースでAurora Serverlessを使用する際の設定注意点)
VPC作成 VPCx1, subnetx2
- VPCページに移動
- VPCsをクリックし『Create PVC』をクリック
- VPC only and more <— moreを選択するとPrivate subnet, Public subnet, Internet gateway, Route tableなど作成できる
- name 『myVPC-001-rag-vpc』
- IPv4 CIDR manual input 『10.0.0.0/16』
- No IPv6 CIDR block
- Tenancy 『Default』ーーー専用は有料なので共有のdefaultにした
- Availabilityを2 <ーーーVectordb Auroraで必要
- Public subnetsも2<ーーー将来Webに必要かもしれない
- Private subnetsを2 <ーーーVectordb Auroraで必要
- NATとVPC endpointsは両方とも0
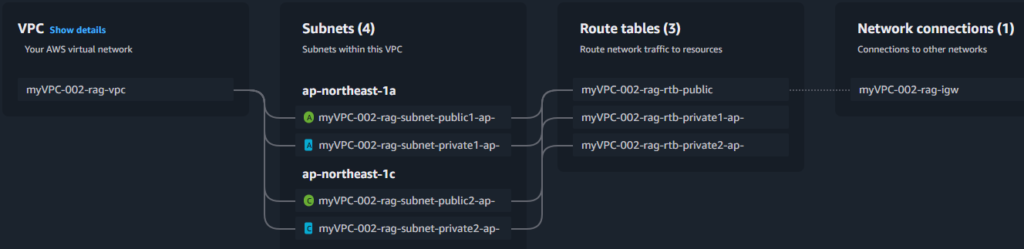
- myVPC-002-rag-subnet-private1-ap-northeast-1a, 10.0.128.0/20
- myVPC-002-rag-subnet-private2-ap-northeast-1c, 10.0.144.0/20
- myVPC-002-rag-subnet-public1-ap-northeast-1a, 10.0.0.0/20
- myVPC-002-rag-subnet-public2-ap-northeast-1c, 10.0.16.0/20
今回は、前回RAGを構築した時に作成した上記VPCとSubnetを使います。 前回はBedrock経由でKnowlegebaseを作ったので、パスワードやSecrets managerの管理はBedrockがしてくましたが、今回はこのあたりも構築しなければなりません。
- Secrets manager–>Store a new secret
- Secret type: Other type of secret 選択
- Key/value pars: adminとpasswordを入れる
- Encryption keyはそのままaws/secretsmanager
- Next
- secret name and description
- secret name: st.chat
- description: credential for st chat (これは私の場合)
- next
- store
- 画面をリフレッシュしないと表示されません。
- aurora and rds –> subnet group –> create DB subnet group
- name: st-chat-subnet-groupt
- description: subnet group to chat.history aurora postgresql db
- 使用するVPCを選択
- add SubnetsのAvailability zonesでは既存のAvailability zoneを2つ選択する。
- 私の場合は、ap-northeast-1aとap-northeast-1c
- Subnetsではpulldownで開いて、ap-northeast-1aのprivate subnetとap-northeast-1cのprivate subnetの2つを選択。
Security Groupを1つ作成
Security Groupはファイヤーウォールのようなもの。 1つはDBに入るのを制限します。 特にポート番号は1つに絞ります。 IPアドレス範囲はVPCに合わせます。
RDS用
- vpc–>security group–>create security group
- name:st.chat.history.rds
- vpcを選択
- Inbound rulesでadd rule
- type: custom tcp
- port range: 5432 <—PostgreSQLのdefault
- Source: custom
- すぐ右の空白欄に半角で、10.0と打ち込むとリストが現れる。 私はVPCのIPのレンジが10.0.0.0/16なのでそのまま入れる。
- Outbound rulesは何も入れない(0.0.0.0/0のまま)
- create security group
Secrets manager
AuroraでClusterを作るとSecrets managerが自動的に生成されます。
- Secret name: st.chat
- Secret key: admin
- Secret value: password
上記以外にもengineや他のキー名と値が生成されます。 なので個別で作成する必要はありません。
AuroraDB Serverless V2作成
- クラスタは計6個のコピーを3つのAvailability zoneに保存して、障害が起きたら自動的に他のインスタンスをプライマリーインスタンスに昇格させてサービス停止しないようにしている。 またデータ修復もする。
- 読み出しの多い用途では、複数のReadレプリカを活用して高速読み出しを可能にしている。
- クラスタは40個作ることができる。
- 各クラスタにwrite instanceは1個でread instanceは15個まで作成できる。
- Write instanceに
- ServerlessのACUはクラスタ単位で増減する。
- 常時稼働のACUはインスタンス単位で増減する。
- Serverlessと常時稼働のインスタンスは同じクラスタに設置できない。
- 開発時はServerlessにして、その後Production時は常時稼働にする場合は、クラスタごとスナップショットを保存して、新しい常時稼働のクラスタに変更しないといけない。
私の場合、今回はServerlessで作成し評価して、将来常時稼働にするので、別の新しいクラスタを作成して、DBインスタンスを設定する。
- Aurora and RDS–> Create database
- Aurora (PostgreSQL compatible)選択
- Hide filters:すべてオフ
- Templates:後で面倒臭いのでProduction
- dev/testからProductionへの変更方法
- インスタンスをReadとWriteの2つにする
- インスタンスのクラスをmクラスからrクラスなどに変更
- バックアップを7日から35日に変更
- アプリケーションサーバーのセキュリティグループだけを許可するInbound ruleの設定
- DB Cluster identifier:dbClusterStChat
- Master username: stchat
- adminは予約後で使えなかった
- Credential management: Self managed
- Master password:password
- Aurora standard
- Serverless v2
- Minimum ACUs: 0
- Maximum ACUs:64
- Pause after inactivity: 00:30:00
- Create an Aurora replica or Reader node in a different AZ
- Don’t connect to an EC2 compute resource
- IPv4
- 作成したVPCを選択:myVPC-002-rag-vpc(私の場合)
- 作成したsubnetを選択:myknowledgebase-subnet-group
- Public access:No
- VPC security group(firewall); Choose existing
- st.chat.history.rdsを選択
- RDS proxyは選択しないが、後で別途作成する。
- 勝手にSecurity groupとかSecretとか作成されないようにする。
- Certificate authorigy:rsa4096を選択。(expirationが長いので)
- これはhttps SSL endpointとして使用する際に使う。
- Lambdaからでもhttpsのみとした場合に必要になる。
- IAM Authentifcationもチェックを入れる。
- パスワードでも通信できるが、IAM Permission設定だけで通信出来るので便利。
- これを選択してもパスワードでも通信できる。
- パスワード通信を無効にしてIAM通信だけにすることも出来る。
- MonitoringはDatabase insights-standardを選択
接続しているVPC確認方法
- Aurora and RDS–>Databasesを選択
- 作成したクラスタの下にぶら下がっている。 DB Identifierの2列右の項目にRoleがあるが、それらはWrite instanceとRead instanceになっている。 それらをクリックしたら接続されているVPCやRDSに付与されたSecurity group等が表示される。
- 【注意】一番上のRegional ClusterをクリックしてClusterはVPCに接続されないのでVPCは表示されない。
RDS proxy接続(使用しない)
今回は作成しない。 RDS Proxyは1億人接続など大量の接続時に有効。 それまではData API接続が有効。
Lambdaはサーバーレスなので、毎回PostgresSQLへ接続確立が必要になる。 多数のLambdaなどが接続する際、接続確立で高負荷になり遅延やコストがかかる。 その場合、RDS Proxyを使うと接続をプールして、Lambdaが使える。 しかしFargtate等を使用する際は、接続を維持できるのでProxyは不要。 Serverless V2を使った場合のProxyの最低料金は8ACU でUSD0.025/ACU時間なので30日で$144となる。 Serverlessでなく常時稼働の場合は1vCPUあたり$13なので、常時稼働でLambdaを使う場合はProxyが必要になる。
Data API接続(これを使用する)
Data APIを使うことにする。 これが一番よい。
- Aurora and RDS—> Databases
- 作成したクラスタ名を選択:dbclusterstchat
- 画面を下にスクロールして一番下に、RDS Data APIとあるので『Enable RDS Data API』をクリック
- Data APIを使うと接続確立が不要になる。
- Lambdaからのアクセスだと毎回接続確立が必要になる。
- Data APIはリクエストだけの課金。 USD0.42/100万リクエストなので、10万人x3000回/月でも$13程度なので、LambdaでもData APIを使い、将来Fargateに移行しても同じアクセス方法のData APIを使い続けてもいい。 そして安定したらData APIもProxyもなしに改修したらいい。
- Data APIは持続的な接続出ないため、フェールオーバーでの接続遅延は発生しない。
Secret作成(もし作りたかったら)
Clusterを作成したら自動的にSecretを作ってくれますが、長い名前になるのでもし自分で作りたかったら以下の手順で作れます。
usernameとpasswordは上記でDBに設定しました。 すると勝手にSecretができていました。 なのでLambdaからはそのSecretを取ってきてDBで接続します。
しかしSecret名が長いので、短い名前で作成したい時は同じ形でSecretを作成します。
- Secrets manager–> Store a new secret
- Credentials for Amazon RDS databaseを選択
- User nameに上記のusernameの値を入れる。 私の場合、stchat
- Passwordに上記のpasswordの値を入れる。 私の場合、password
- Encryption key:aws/seretsmanagerのまま
- 接続するDBを選択する
- 上記でCredentials for Amazon RDS databaseを選択してるので
- DBを選択できる。 これを選択しておくと、後日Automatic Rotationを有効にしたら、SecretがLambda関数を自動で作成してSecretがRotateしたpasswordやusernameでDBのusernameとpasswordをAlter(変更)してくれる。
- しかし初期値のUsernameとPasswordがDBと一致していないといけない。 今回は一致させている。
- Secret name:st.chat.new
- Resource permissionを入れる。(例を下に記述してます)
- Next
- Automatic Rotationはしない(実運用時はしたほうがいい)
- DBを選択している
- Automatic Rotationを有効にすると、自動的にLambda関数が作成され、SecretのパスワードやUsernameが変更(Rotate)されると、設定してRotation ScheduleがEventBridgeのスケジュール機能を使い、そのLambda関数が実行され、Lambdaが新しいPasswordに切り替えてくれる。
- Rotationがうまく行かない場合は以下を設定する。
- Retrieve secret values–> Edit
- resourceIdを追加
- Aurora DBのclusterをクリックするとcluster-で始まるResource IDが表示されるので、valueにコピペする。
- engineのpostgresからaurora-postgresに変更する。
Lambda設定
- Data API接続であれば、VPCに接続しなくてもそのまま起動してAurora Serverless v2 PostgreSQLにアクセスできる。
Aurora PostgresSQL DB作成
DB作成
インスタンスはあるが、まだDBもTableもない状態なのでDBでを作成。
- Aurora and RDS –> Query editor
- Clusterを選択 (dbclusterstchat)
- Database username : Add new database credential
- Username、Password : clusterを作成した時に作ったusernameとpasswordを使う
- Username: stchat
- Password: password
- name of the database: postgres
- まだDBがないので、デフォルトで存在するpostgresという名前のDBに接続する。
- Connect to databaseをクリック
- Runを実行
- 下のRow returnsに結果が表示される。
- Serverless v2なので、最初はエラーになる。 The Aurora DB instance xxxxxxxxxxxx is resuming after being auto-pausedとか表示される。
- Serverless v2が立ち上がるまで2分強かかる場合がある。 どの程度アクセスがなかったかによる。
- Resumingエラーが表示されなくなるまで、20秒ごとくらいでRunを実行する。
- Rows returnedに表示されたらQuery EditorでClearをクリックして入力フィールドを消して、以下を実行して新しくDBを作成する。
- CREATE DATABASE st_chat_db;
- 『.』や『-』は使わないこと。
- db名やtable名は全て小文字が推奨。
- Connect to databaseをクリック
テスト接続
- Query Editorが開くので先程作ったDB(st_chat_db)で接続。 UsernameとPasswordは先ほどと同じ。
- 接続できればDBができているので、次はTable作成。
Vector DB作成
同じCluster内の同じDBに新しくVector検索用のtableを作成する。
PostgreSQL16以上の場合は、Query editorで以下を実行して、Cluster内のDBでpgvectorを使えるようにする。 pgvectorはPostgreSQLの拡張機能でPostgreSQLでvector類似度検索(コサイン類似度、ユークリッド距離)などができるようになり、Vector RAGとして活用できる。 BedrockのKnowledgebaseよりもフレキシブルに作成できるので、精度を上げることができる。
//Databaseの一覧表示 CREATE EXTENSION vector
Table作成
- st_chat_dbに接続した状態でQuery Editor以下の通り作成。
- Query EditorにCREATE TABLE table_nameを記述し()内に各列の定義を記述する。
CREATE TABLE st_chat_history_table ( primarykey bigserial PRIMARY KEY, userid text NOT NULL UNIQUE, themename text NOT NULL, chatid bigint NOT NULL CHECK (chatid >= 0), userinput text, botresponse text, timestamp timestamptz DEFAULT now() ); -- userId用のインデックス CREATE INDEX idx_st_chat_history_userid ON st_chat_history_table (userId); -- timestamp用のインデックス CREATE INDEX idx_st_chat_history_timestamp ON st_chat_history_table (timestamp);
//Databaseの一覧表示 SELECT datname FROM pg_database; //存在するTableの一覧表示 SELECT table_name FROM information_schema.tables WHERE table_schema = 'public'; //特定のテーブルの項目表示 SELECT * FROM information_schema.columns WHERE table_name = 'st_chat_history_table'; //テーブル自体全削除 DROP TABLE st_chat_history_table;
メモ
Aurora PostgreSQL <16と古い場合にvectorを設定する方法。
以下は、古いPostgreSQL engineを使っている場合だった。 私の使っているPostgreSQL 16にはVectorDBが標準装備されているので、Custom Parameter Groupを変更する必要なかった。
Vector DBを操作できるpgvectorを使用できるように設定変更。 Default parameter groupの内容には含まれておらず、default parameter groupの内容は変更できないので、ClusterにDefault parameter groupが選択されていたら、Custom parameter groupを作り、pgvectorを登録する。 さらにClusterが使っているengine typeが必要なので予め調べておく。
- Aurora –> Databases –> 対象クラスタをクリック
- Configurationタブクリック
- Parameter groupとEngine Typeが記載されているのでメモっておく
- Aurora–>左メニュー parameter groups-> Create custom parameter group
- name: MyCustomParameterGroupPgvector
- Description: TO user pgvector
- Engine type: Aurora PostgreSQL
- Parameter group family: aurora-postgresql16(私の場合は16.6だったので)
- Type: DB Cluster Parameter Group
- Cluster全体に対するパラメータ
- Create
- 作成できたら、作成したCustom parameter groupを選択して、Edit
- Modifiable parameterのshared_preload_librariesのvalueにvectorと追加する。
- 何も入っていなければ『vector』と入れる
- なにか値が入っていれば末尾に『,vector』と追加する。スペースは入れない事。
Vector DB用Table作成
- 以下のようなテーブルを作る
- Vector embeddingはBedrock Cohere multilingual v3を使うので1024次元
- Vector検索高速化の為に、chat_vectorにIndexを付ける。
- HNSWは、大規模なベクターデータセットに対して高速な近似最近傍探索(Approximate Nearest Neighbor Search: ANNS)を実現するためのインデックスアルゴリズムです。
- ector_l2_ops は、PostgreSQLの拡張機能であるpgvectorにおいて、HNSWインデックスを構築する際に**「どの距離計算方法を使って近さを定義するか」を指定する演算子クラス(Operator Class)**です。 この場合L2距離(ユークリッド距離)。 正規化してl2を使うと距離が角度となりコサイン類似度と完全に一致する。 なのでLambdaでEmbeddingを計算して正規化して格納すること。
CREATE TABLE st_chat_history_vector_table (
primarykey BIGSERIAL PRIMARY KEY,
userid TEXT NOT NULL,
theme TEXT NOT NULL,
chatid BIGINT NOT NULL CHECK (chatid >= 0),
chat_summary TEXT NOT NULL,
metadata JSONB, -- ★推奨: JSONB型に変更
chat_vector VECTOR(1024) NOT NULL -- ベクターデータは必須のためNOT NULLを追加推奨
);
-- ベクター検索を高速化するためのHNSWインデックス
CREATE INDEX ON st_chat_history_vector_table USING hnsw (chat_vector vector_l2_ops);
Lambdaからのアクセス方法はまだここに書けてません。(が出来ています。時間がある時に追記します。)
Data API か Conn(Proxy)選択
量が少ない場合はData APIが簡単で安い。 しかしTPS(Transaction per second)が増えるとAurora PostgreSQL ClusterごとにProxyが必要
| 項目 | Aurora Data API | Proxy(Conn 接続) |
|---|---|---|
| 接続方式 | コネクションレス(HTTP) | コネクション維持(TCP) |
| Lambda との相性 | ◎ 非常に良い | △ コネクション管理が必要 |
| レイテンシ | 20〜100ms | 1〜5ms(高速) |
| スループット | 低〜中 | 高 |
| 同時実行耐性 | 中 | 高 |
| コスト | 安い(Proxy不要) | 高い(Proxy料金+DB負荷) |
| 運用の複雑さ | 低い(簡単) | 高い(接続管理が必要) |
| 適した用途 | 軽いクエリ、イベント駆動、低頻度 | 高頻度、大量更新、複雑なJOIN |
| 失敗時のリトライ | 容易 | コネクション切断時に複雑 |
| Lambda のコールドスタート影響 | 小さい | 大きい(接続確立が必要) |
| Aurora CPU 負荷 | 低〜中 | 中〜高(大量接続で増える) |
| 1秒あたりの Aurora 更新数 | 推奨方式 |
|---|---|
| 〜50 TPS | Data API(余裕) |
| 50〜100 TPS | Data API(問題なし) |
| 100〜300 TPS | Data API(ギリギリ) |
| 300〜500 TPS | グレーゾーン(切り替え検討) |
| 500〜1000 TPS | Proxy(Conn)推奨 |
| 1000 TPS 以上 | Proxy(Conn)必須 |
ユーザー管理、課金集計などは1つのAurora PostgreSQL Clusterにする。 読み出しがヘビーなRAGは別Clusterにしなければいけない。
CloudWatchからTPSを取得してDynamoDBに保存するLambdaコード
検証していません。 しかし例として載せておきます。
CloudWatchは自動的にTPSが送られる。 保存期間は15ヶ月で自動削除。
import boto3
import datetime
import os
cloudwatch = boto3.client('cloudwatch')
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(os.environ['TPS_TABLE'])
def lambda_handler(event, context):
now = datetime.datetime.utcnow()
start = now - datetime.timedelta(minutes=1)
# CloudWatch から Aurora の TPS(CommitThroughput)を取得
response = cloudwatch.get_metric_statistics(
Namespace='AWS/RDS',
MetricName='CommitThroughput',
Dimensions=[
{'Name': 'DBClusterIdentifier', 'Value': os.environ['AURORA_CLUSTER_ID']}
],
StartTime=start,
EndTime=now,
Period=60,
Statistics=['Maximum']
)
datapoints = response.get('Datapoints', [])
if not datapoints:
return {"status": "no data"}
tps = datapoints[0]['Maximum']
# 月のキー
yyyymm = now.strftime("%Y%m")
# DynamoDB に書き込み
table.put_item(
Item={
'PK': f"TPS#{yyyymm}",
'SK': now.isoformat(),
'tps': tps
}
)
# トップ10だけ残す(古いものを削除)
prune_top10(yyyymm)
return {"status": "ok", "tps": tps}
def prune_top10(yyyymm):
# 月の全TPSを取得
response = table.query(
KeyConditionExpression="PK = :pk",
ExpressionAttributeValues={":pk": f"TPS#{yyyymm}"}
)
items = response['Items']
if len(items) <= 10:
return
# TPS の高い順にソート
items_sorted = sorted(items, key=lambda x: x['tps'], reverse=True)
# 11位以下を削除
for item in items_sorted[10:]:
table.delete_item(
Key={'PK': item['PK'], 'SK': item['SK']}
)

コメント