
DynamoDB
NoSQLなので書込は軽量で高速ですが、複雑な検索(クエリ)は出来ず、基本的に全件取得(Scan:高価)かPrimary Keyでの取得が基本になります。 今回は、Primary KeyはPartition KeyとSort Keyの複合キーにしています。 IoT用のBig Dataに適していますが、時系列の場合はTimestreamの方が便利です。 今回は無期限の25GB無料枠+月2億リクエスト使えるDynamoDBを使います。 私の場合、以下の様に進めていきます。
- Partition KeyはdeviceID
- Sort KeyはtimestampでISO8601形式のUTC
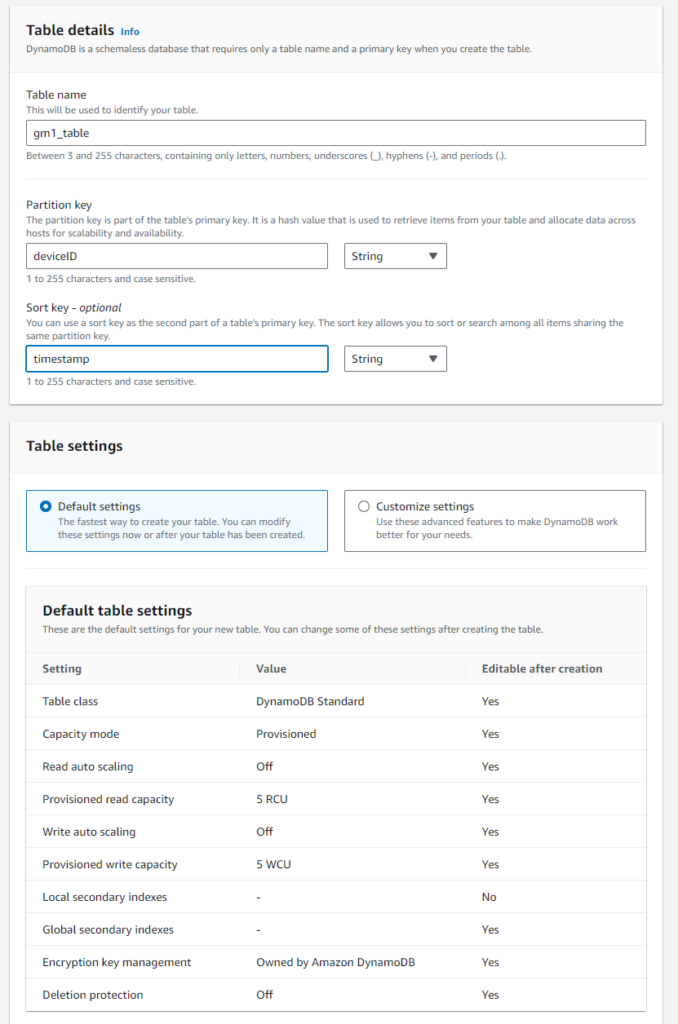
テーブル作成
- 『DynamoDB』画面に移動
- 左メニューから『Tables』~『Create table』、以下の様に記述し、画面の下までスクロールして『Create table』
- Table nameは意味はありませんが『gm1_table』としています。
- Partition keyは、完全一致検索なのでDeviceType.ThingName形式とします。(DeviceIDだとThingNameと別管理で作らないといけない為)
- Sort keyは、μs単位までのISO8601とします。 これでPartition key+Sort keyで一意になるようにする。
- 余計な課金をされないようにデフォルトのProvisionedモードで5CUづつReadとWriteに割り当てています。(CU:Capacity Unit=容量単位)
- 画面下にスクロールダウンして『Create table』クリック
DynamoDB用語や説明
- Primary key(=主キー)
- Unique(一意)でなければならない
- 2パターンある
- Primary key = Partition key の場合。
- Primary key = Partition key + Sort key (複合プライマリーキー) ⇦今回はこれを使う
- 間違えて既にある複合プライマリーキーを使って書込むと、既存のデータに上書きしてしまうので注意。
- Partition key(=PK=Hash=Hash attribute=Hash key)
- Primary keyの一種
- Partition keyに基づいてデータが分散される
- Partition keyは検索で必ず使われる
- Partition keyだけをPrimary Keyとする場合は、Partition keyの値は一意である事。 この時Sort keyは使えない。
- Partition keyは
- Partition keyでの検索は完全一致のみ
- Partition keyのKeyTypeはHASHのみ。 しかしHASH KeyTypeは以下の型がある。
- S:string ーーーこれだけで十分
- N:number ーーー多分DECでSより高速
- B:binary ーーー多分HEXで最高速、桁を短く出来る
- Partition keyでテーブルはパーティションに分割される。 各パーティションでCU(Read/WriteするUnit数)が分割されるので、各パーティションのデータ容量はできるだけ均一になるようにする。
- Sort key(=SK=Range key=Range attribute)
- Primary key+Sort keyで一意になる事
- begins_with、between、>、< などの演算子による範囲のクエリを使用して検索するためのキー
- Sort keyの検索は前方一致
- Sort KeyのKeyTypeは、RANGE(string型)かBINARY(binary型)
- 文字列をRANGEとしているのは、ここに文字列のISO8601の時間を入れ範囲指定すると想定したためらしい
- 前方一致検索ができるのでSortKeyには以下の様に入れる事が出来る。
- [country]#[region]#[state]#[county]#[city]#[neighborhood]
- しかし今回はSort KeyにTimestampを入れる
- 異なるItem(行)のSort KeyにはTimestampや特定の文字列をitemごとに変更する事ができる。 データの場合はTimestamp、リンクの場合は特定の文字列等。
- Secondary Index key(複合プライマリーキーに足して増やせる)
- Local Secondary Index(LSI)
- Partition keyはそのまま
- 本来のSort Keyとは別に、コピー版として指定した属性をSort Keyに見立てたテーブルを作るような感じ
- 複合キーテーブルのみ
- 最大5個、上限10GB/Partition
- テーブル作成時に作成後変更不可
- 強力な整合性のある読出可
- Partition内でしか検索できないが、テーブル容量は変わらない。
- Global Secondary Index(GSI) —-UserIDに使用する?
- 全てのPartitionにまたがるインデックス
- 最大20個、Partitionの上限なし ーーー
- 追加削除可能
- (使用する事)高速で安価
- Partition keyとSort keyーを持つインデックス。
- 前方一致検索が出来る
- しかしクエリは2要素、GSIを1要素とすると、Sort KeyかPartition Keyのどちらかしか組み合わせてクエリできない。
- Partitionをまたがって全領域を検索できるが、GSIの数だけテーブルが増えるので容量が増える(コスト増加)
- ALL、KEY_ONLY、INCLUDEの3つからGSIタイプを選択できる
- ALL
- 全ての値を取得するため、テーブル容量がGSIあたり100%増加する。
- KEY_ONLY
- Partition keyやSort keyだけ取得できるので、容量は10%程度増加。
- INCLUDE
- Keyは指定しなくても取得されるが、それ以外に取得したいAttribute名を指定する。
- Keyと指定したAttribute名の容量分が増えるので大体20%~80%増加する。
- 容量を減らすのがメインで、多少遅くなって良いのであれば、KEY_ONLYを選択して、取得したKeyで再度Queryするのも一つの手かもしれない。
- Local Secondary Index(LSI)
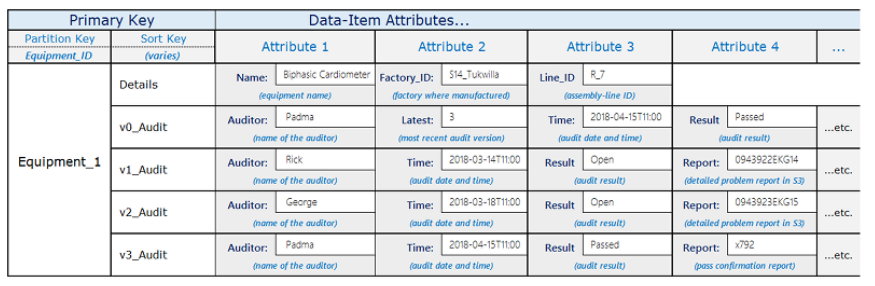
テーブル例
- quaryAPIを使ってキー指定して取得(検索条件はkeyだけ、Attributeは使えない)
- GetItem
- Partition Keyだけで単一アイテム取得
- 例えば、s3ファイルのURLを保存してあるitem取得の場合など
- Sort keyも含めた検索は出来ないので、時間範囲指定の場合はqueryを使用する。
- BatchGetItem
- 複数のPartition Keyでの検索。 Sort keyは検索に使えません。
- 最大16MB、100アイテム取得
- scan(使わない事)
- 全件走査(全てのデータ取得)
- Capacity unitを使うのですぐ有料になる
- 負荷が大きい
- Attributeで絞り込んでscanしても全件読み出した後にAttributeでフィルターをかけるのでキCapacity unitを使う。
- Scanで1回の読み出しで1MBまで。 それ以上の読み出しはループ処理が必要。
- query
- Lambdaでは通常このqueryを使用して読出しをする。
- インデックスを使って取得
- KeyConditionExpressionでPartition KeyとSortKey(範囲指定)を入れてqueryする。
- <1MB/回
begins_with、between、>、<
- BatchWriteItem
- 最大25アイテム/回 無料枠25ユニット/秒
- BatchWriteItemはPutItem、UpdateItem、DeleteItemと組み合わせて実行します。 なのでDeleteItemと組み合わせるとBatchWriteItemの1リクエストで25のアイテムを削除できます。
- PutItem
- Lambdaでデータ書込み時はこれを使う
- DeleteItem
- 1アイテム削除時
- Read/Writeの注意点
- Capacity Unit(CU)という課金単位がありテーブルに設定されたCUの範囲内でのRead/Writeをしないと課金が増えてしまいます。
- Read Capacity Unit(RCU) — ConsumedReadCapacityUnitsメトリクスで監視可能
- Write Capacity Unit(WCU) — ConsumedWriteCapacityUnitsメトリクスで監視可能
- 1回/秒(4KB)の強力な整合性のある読込(1RCU)
- 2回/秒(4KBx2)の整合性のある読込(2RCU)
- トランザクション読込:1回/秒(4KB)(2RCU)
- トランザクション書込:1回/秒(1KB)(2WCU)
- ThrotleEventsメトリクスで負荷制限が発生したどうかを監視可能
DynamoDBのテーブル設計時の考慮点
- 1アカウント10,000テーブル、1リージョン256テーブル(しかしテーブルはできるだけ1つにまとめる事)
- テーブルをできるだけ少なくする事
- スケーラビリティ向上
- アクセス権限管理減少
- オーバーヘッド削減
- バックアップコスト削減になる
- 物理パーティション数を増やしデータを分散してスケーリング
- 関連するデータは同じテーブルにまとめる
- 属性値にkeyと値のJSON形式で入れるか、個別値を入れるか考える
- JSONの場合、
- json.dumpsを使って文字列にした後に属性に格納する。
- ユーザーが自由にKeyと値を設計出来る
- 使いやすそうなので実際のIoTのBig DataではJSON形式で複数のデータを一つの要素に格納する。(DynamoDBではPartitionKeyとSortKeyでしかクエリできず、データ名ではクエリ出来ないので、とりあえずJSON形式で全て呼び出し、外部プログラムで必要データを抜き出す。)
- DynamoDBから抜き出してグラフ化やPython側でのAI処理の抜き出しに時間がかかる。 しかしDynamoDBからの抜き出しは早いかも。
- ユーザーが間違うと処理でエラーが発生する(ユーザー定義JSONを作らせて、書込む際にエラーチェックを走らせるか)
- スカラ値の場合
- 値の指定がややこしい
- 消費量は若干少ないような気がするが、逆に各セルに分かれるので多いかも
- DynamoDBからの抜き出しに時間はかかるが扱いが簡単
- 配列(List)の場合
- JSON形式のキーの値でも配列を使えるので、ListだけをIoTでどう使うか分かっていません
- JSONの場合、
- 属性(attribute)
- 格納した実際のデータの事
- Partition KeyとSort Key以外の部分
- 最大256個/itemの属性を持てる
- 1テーブルでは最大数の定義はなく数千個持てるが、多いとパフォーマンスに影響するらしい。
- DynamoDBはスキーマレスなのでテーブル設計時に各項目の型を決める必要がない。
- Putする時にデータ型を指定してPutする。
- Map、Listの場合は、各属性に追加3byte必要。 更に、各属性の各要素に追加1byte必要。
Item
- データの1行の事
- 最大400KB/item
強い整合性
- 強い整合性・・・変更が完了するまで他の人は古いデータを参照できない
- 結果整合性・・・変更が完了していない状態でも他の人は古いデータを参照できる
Capacity Unit
1秒当たりの書込み、読出しkB(キロバイト)に応じて課金される。 負荷による課金のようなもの。 その他にも転送量や保存料などでも課金される。
書込み WCUが1kB/秒で1WCU消費するので、1item当たりのWriteを1kBか100Bか200B位にした方が良さそう。
容量
各item(行)には以下が含まれる。
- Partition Keyの属性名と値
- Sort Keyの属性名と値
- 各属性名とその属性の値
スループット
テーブルへの書込や読込能力の事。 通常は、読込は秒1RCU(強力整合)か秒2RCUか1WCU。
プロビジョニング、オンデマンド
プロビジョニングは、料金が多くならないように予め最大で使えるスループット能力を設定することができる。(キャパシティーモード)
オンデマンドはDynamoDBが自動的にスループットをスケーリングする。
ミッションクリティカル(≒特に重要なプロセス)、DynamoDBの場合は以下の場合
- データの可用性: DynamoDBは高可用性を提供し、データへのアクセスが常に確保されています。データの可用性がミッションクリティカルなアプリケーションやサービスにとって不可欠です。
- スケーラビリティ: ミッションクリティカルなアプリケーションは通常、変動する負荷に対して柔軟にスケーリングできる必要があります。DynamoDBはスケーラブルで、需要に合わせて簡単に拡張できるため、ミッションクリティカルな要件を満たすのに適しています。
- データの耐久性: DynamoDBはデータの耐久性を確保し、データが損失しないようにします。ミッションクリティカルなデータの保護が求められます。
- パフォーマンス: ミッションクリティカルなアプリケーションは高いパフォーマンスが期待されます。DynamoDBは低遅延で高性能なデータアクセスを提供するため、これも重要な要素です。
射影(Projection)
コピーのようなもの。
クエリやスキャンを実行する際に、各Item(行)のどの属性を取得するかを指定できます。
- 全射影(All Projection): すべての属性を取得します。これはデフォルトの射影オプションであり、クエリやスキャンで何も指定しない場合、すべての属性が取得されます。
- 主キー射影(Key-Only Projection): 主キーのみを取得します。これはテーブル内の主キー情報だけが必要な場合に使用されます。余分なデータを取得せずに効率的にクエリを実行することができます。
- 特定の属性のみを射影: クエリやスキャンの際に、取得したい特定の属性名を指定して射影できます。これにより、必要な情報のみを取得して帯域幅を節約することができます。
shard
テーブルの物理的な分割単位で、DynamoDBは分散データベースであり、大量のデータを効率的に処理するためにテーブルを複数のシャードに自動的に分割します。
それぞれのシャードは独自のパーティションキー範囲を持っていて、パーティションキーはデータを均等に分散するために使用され、各パーティションキー範囲が1つのシャードに対応しています。
テーブルクラス
- Standard Table Class(初期値)
- アクセスに対するコストは低いが、保存量によるコストは高い
- 頻繁にアクセスされるデータ(AI解析など)
- Standard-Infrequent Access
- アクセスに対するコストは高いが、保存量によるコストは安い
- あまりアクセスされないデータ(注文履歴、アプリケーションログ、過去の実績等)
データ保持
35日を超えたデータは、削除するかRedShiftに転送して保持するのが良い。 DynamoDBの保存コストは、US$0.114/GB。 DynamoDBアドバンスド機能のDynamoDBコールドストレージでUSD0.0342/GB
RedShiftはデータウェアハウスで、分析用に整形して保存でき、保存コストもUS$0.025/GBと最安のクラスタースナップショットのUS$0.023/GBとほとんど変わらず、読み出して分析する際、別のストレージに転送しなくてよいのでその際の転送(復元)コストがかからない。
TTL(Time To Live)
各テーブルにTTLを設定できる。 TTLは、itemが書き込まれてから削除されるまでの時間設定。 例えば40日で設定すれば、itemは41日後に自動的に削除されるので、テーブルの容量を抑える事が出来、課金料金を節約できる。 41日後と言いましたが、公式ドキュメントには『期限切れから 48 時間以内に削除します。』とあります。 しかし大体は40日が経って11~20分後には削除されているようです。
データと型
- データ:全ての名前はUTF-8、Case sensitive、
- Index:3~255文字 ‘a-zA-Z0-9_-.’ 下線、ダッシュ、ドット
- attribute(属性):<64KB
- Number:64bit浮動小数点
- String:UTF-8、Binary Unicode、時刻ISO8601文字列
- 属性値:空OK(key、index以外)
- Binary:max400KB
- DynamoDBに送信する前にbase64エンコード形式のバイナリ値をエンコードする必要あり
- 属性値:空OK(key、index以外)
- Boolean:true、false
- null:
- List:順序型、[ . . .]、配列、最大32レベル、400KB
- 属性値:空OK
- Map:JSONオブジェクト、最大32レベル、400KB
- 属性値:空OK
- String set:文字だけの配列もどき
- 属性値:空不可
- 空の行があってはいけないので使いにくく、使う時はテーブルを分けて使うのが良いかも。
- Number set:数字だけの配列もどき
- 属性値:空不可
- Binary set:Binaryをbase64encode文字列だけの配列もどき
- 属性値:空不可
- 時間(Timestamp)の型は無いため、ISO8601形式をstring形式で持つのが良い
- 2021-02-21T18:08:22Z ーーーDateとTimeは『T』で分かれている。
- ZはUTC時間で、DynamoDBはUTC時間を保持するように推奨している。
- 日本時間で範囲指定の場合は、日本時間をUTCに変換して範囲指定する。
- 地区時間のまま保存する場合はIANAタイムゾーン名(Olsonデータベース)を入れる(案)”Asia/Tokyo”等
aws dynamodb query --table-name date-time-test --key-condition-expression 'Id = :Id and DT > :ts' --expression-attribute-values '{":Id" : {"S": "A1"}, ":ts" : {"S": "2022-07-12"}}' --return-consumed-capacity TOTAL
DynamoDBできない事
- テーブル結合不可
- 部分一致検索(前方一致は使える) PartitionKeyでは部分一致は使えない。 Global Secondary Indexを使用する事が一般的。
参考 queryで1MB以上の場合の処理
- Query操作で1MBを超える結果を取得する場合、DynamoDBはLastEvaluatedKeyを返します。この値を使用して、次のクエリを実行して結果を取得する必要があります。
- Lambda関数内で、Query操作をループさせて結果を取得します。LastEvaluatedKeyが返される限り、次のクエリを実行して結果を取得し続けます。
import boto3
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('YourTableName')
def query_dynamodb():
response = table.query(
KeyConditionExpression=Key('PartitionKey').eq('YourPartitionKey'),
# その他のクエリ条件を追加
)
items = response['Items']
while 'LastEvaluatedKey' in response:
response = table.query(
KeyConditionExpression=Key('PartitionKey').eq('YourPartitionKey'),
# その他のクエリ条件を追加
ExclusiveStartKey=response['LastEvaluatedKey']
)
items.extend(response['Items'])
return items
def lambda_handler(event, context):
result = query_dynamodb()
# 結果の処理
参考 BatchGetItemで100 itemを超える場合の処理
import boto3
dynamodb = boto3.client('dynamodb')
table_name = 'YourTableName'
# 取得するアイテムの主キーのリスト
keys_to_get = [
{'YourPartitionKeyName': {'S': 'Value1'}},
{'YourPartitionKeyName': {'S': 'Value2'}},
# ここに全ての主キーを追加
]
# BatchGetItemリクエストを作成
response = dynamodb.batch_get_item(
RequestItems={
table_name: {
'Keys': keys_to_get
}
}
)
# 結果を処理
for item in response['Responses'][table_name]:
print(item)
# 残りのアイテムがあるかどうかを確認
while 'UnprocessedKeys' in response:
response = dynamodb.batch_get_item(RequestItems=response['UnprocessedKeys'])
for item in response['Responses'][table_name]:
print(item)
参考 IoTにはDynamoDBかTimestreamか
- DynamoDB強み
- データをJSONで格納できる。(複数の値を格納可能)
- テーブルを無限に拡張できる
- TimestampがISO8601形式なので分かりやすい。 特にテスト段階時。
- サンプルが多い
- 12ヵ月無料枠がある(Timestreamは30日限定)
- Timestream強み
- 時系列データを扱いやすい
- SQLが使え分かりやすいし、データを取り出しやすい。
将来IoTではTimestreamがメインで多くのデータの格納や動画等をs3に格納した際のリンクの格納の場合のみDynamoDBったり、重要情報を格納するのにRDBを組み合わせて使うのがよさそう。 今回は分かりやすいTimestampを使えるDynamoDBを使用します。
参考 Timestream
将来的にはTimesreamに移行した方がよさそう。 以下は調べた内容、
- Tokyoリージョンで可能になっていた。(3年前はN.Virginiaとか米のみだった)
- データ(Measure)ではJSONで書き込んでも、全てのキーが、Timestreamの各行に分かれる。 その際、書込んだキー&値には同じDimension(DynamoDBのPartitionKeyのようなもの)が書き込まれるTimestampとなる。
- 1アイテム(行)最大10kB
- キーはDimensionとTime Series(Timestamp)でクエリができる
- 最小時間単位はns、フォーマットはUnix Epoch Time。 1970年1月1日0時からの数値。 秒、ミリ単位の場合それぞれ10桁、13桁の数字になる。(分かりづらいが計算は速い)
- 時間範囲指定ができる
- Dimension名の長さは最大64文字
- Dimensionはクエリ用の情報(デバイスIDなど)、Metaとも呼ぶ
- Measureは、JSON形式で最大100のキーと値のペアを格納できる。 しかし多くなると書き込み速度が遅くなる。
- Item当たりにPartition Keyの属性名、Sort Keyの属性名、itemの属性名等は格納されないので軽い。
- 書込み速度はDynamoDBの方が1.25倍速い
- 設定はTimestreamの方が簡単
- Timestreamにも古いデーターを自動削除設定あり。
- 最大1000テーブル/アカウント、500TB/テーブル (DynamoDBは無制限)
- 格納したJSONが各Measureのキーと値で格納されるので、DeviceID+時間+キー名でクエリしやすい。 Dynamoの場合、JSONで取り出してPythonで抜き出す処理が必要になる。
- QueryはSQLを使うのでわかりやすい
- 手動レコード削除できない。 保持時間経過後自動削除のみ。
- バックアップ機能やS3へのエクスポート機能がない
- データは書き込み後、メモリに入る、その後SSDに保存されて、その後マグネティックストアに保存される。 これらは設定で自動的に実行される。
- データがメモリ、SSD、マグネティックに保存されていても、クエリで一連のデータとして読みだされる
- 一回のクエリでの読み出し制限なし
- 最長保存期間は1年
- Transaction機能はない。(IoTでは特に不要)DynamoDBのTransactWriteのような機能はない
- 料金(Timestream:DynamoDB)USD
- 書込み1KBx100万件 0.5:1.25
- 保存 Timestream
- メモリ:0.01/GB-hour
- SSD: 0.01/GB-day
- マグネティック: 0.01/GB-月 —最大1TB
- Timestream Backup ウォーム 0.114/GB-月
- Timestream Backup コールド 0.0342/GB-月
- 復元Timestream
- Timestream Backup ウォームストレージ 0.171/GB月
- Timestream Backup コールドストレージ 0.228/GB月
- 保存DynamoDB
- Backup ウォーム 0.114/GB-月
- Backup コールド 0.0342/GB-月
- Redshift クラスタースナップショット 0.025/GB-月
- 復元DynamoDB
- S3 ウォームストレージ 0.06/GB-月
- Backup ウォームストレージ 0.171/GB
- Backup コールドストレージ 0.228/GB
- Redshift クラスタースナップショット 無料
SELECT time, temperature FROM myTable WHERE device_id = 'myDeviceID' AND time BETWEEN '2022-01-01T00:00:00Z' AND '2022-01-02T00:00:00Z'

コメント