
(2024/9)
ここではDynamoDBからデータを読み出し、CSVでs3保存します。
全体の流れ
- LambdaでDynameDBからデータを取得して、データを整形してcsvに入れs3に格納する
- AmplifyのAngularを使って、s3のcsvを取得してグラフにしてwebに表示する
- 本来はDynamoDBのデータをもとにSageMakerでAI計算してWeb表示したいが、十分な学習データがないため、Nasa Turbofanのデータを使う。
- ローカルPCでNasa Turbofanの残存期間算出のモデル作成と学習して保存
- 保存したモデルと学習したパラメータとテストデータをs3に保存
- Angular WebからのボタンクリックでSageMakerから、モデルとテストデータを読み込み残存期間を算出し、Web表示
本来AmplifyでDynamoDBから直接データを取得する方法もありますが、今後SageMakerでDynamoDBのデータをAI処理させたいので、AI用に前処理したcsvをs3に保存して、SageMakerで学習、predictさせて結果をs3においてWeb表示させる為です。 AI処理は最終的に一日の一定時間にスケジュールして実行させる必要があるので、過去の結果も見れるように結果はs3に置いておきたいのです。 その為、今回はs3経由でのWeb表示をします。
Create Function(Lambda関数作成)
Lambdaは元々ラムダ計算という関数の定義を扱うための記法でLambda λ記号が使われていました。 これに因んで、Pythonではlambdaを記述して無名関数を定義します。 AWS Lambdaもこれに因んでいると思うので、AWS Lambdaはサーバーレス(EC2などのサーバを立てなくてもいい)で関数を実行するためのものです。 なので関数(Function)を作らないと何もできません。
- Lambda~『Create function』で、
- 『Use a blueprint』を選び
- 『Blueprint name』を『Hello world function python3.10』を選び
- 『Function Name』を入れ(私の場合MyFuncDynamoDBtoS3と言う名前にしました)
- 『Create a new role with basic Lambda permissions』を選択し
- 画面下の『Create function』をクリックでFunctionが作成しました。
Permission(権限)設定
- まずFunctionがDynamoDBや3s等のサービスアクセスするpermission(アクセス権限)の設定します。
- 因みにFunction作成時最低限のLambdaのpermissionは設定されているので、CloudWatchにログを出力するためのpermissionは既に設定されています。
- 『Configuration』~『Permission』をクリックして作成されているRole nameをクリックします。
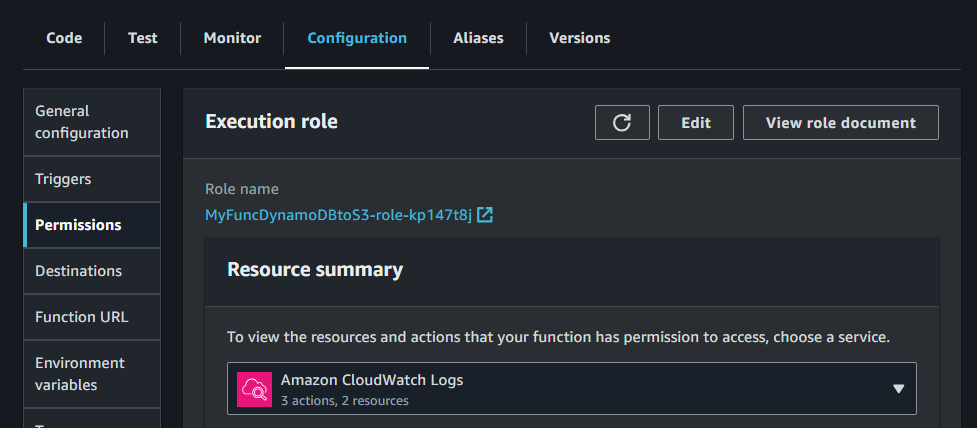
- IAMのRolesの中に飛んでいくので
- 『Add permissions』~『Add policies』を選択して
- 『dynamo』や『s3』で検索し両方FullAccessのPolicyを追加します。
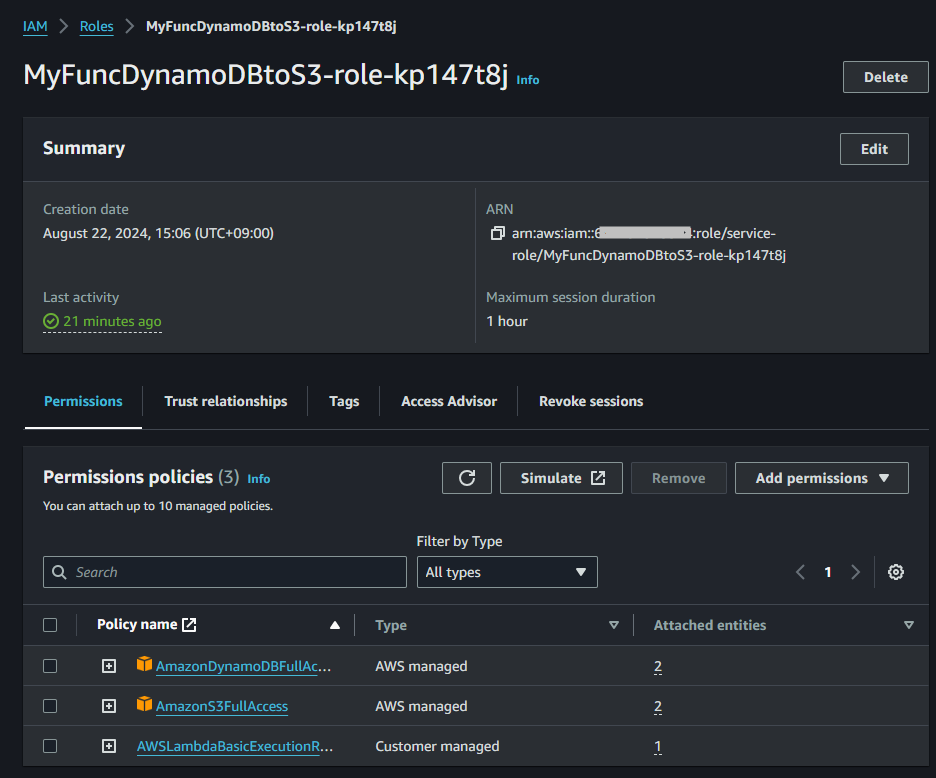
- これで以下の様に3つのPolicy nameが表示されます。
始める前に
DynamoDBからtimestampの範囲(between)指定で取ってきたデータはDictのこんな感じ。
- 1階層目にItems、Count、ScannedCount、ResponseMetadataとなっているので、まずres[Items] だけ抜き出す。
- Items内はvariable、deviceID、tiemstampがあるが、variableは2階層になっている。 csvは1行目に項目名入る1階層なのでvariable部分を1階層にフラット化する(flatten)。
- フラット化する時、Decimal()の部分はDecimal()を削除して数値だけの文字としてcsvに入れる。
{'Items': [{'variable': {'PLC_PRG.VarTimeCur1': {'val': Decimal('0'), 'type': 'Int64'}, 'GVL.MyVariable': {'val': Decimal('6789'), 'type': 'Int16'}, 'GVL.MyCount': {'val': Decimal('20001'), 'type': 'Int16'}, 'PLC_PRG.VarTimeCur0': {'val': Decimal('2400'), 'type': 'Int64'}, 'GVL.MyString': {'val': 'HELLO ICHIRI', 'type': 'String'}}, 'deviceID': 'PLC.GG-gm1-00', 'timestamp': '2024-05-08 03:10:39.953000'}, {'variable': {'PLC_PRG.VarTimeCur1': {'val': Decimal('2420'), 'type': 'Int64'}, 'GVL.MyVariable': {'val': Decimal('6789'), 'type': 'Int16'}, 'GVL.MyCount': {'val': Decimal('20001'), 'type': 'Int16'}, 'PLC_PRG.VarTimeCur0': {'val': Decimal('20000'), 'type': 'Int64'}, 'GVL.MyString': {'val': 'HELLO ICHIRI', 'type': 'String'}}, 'deviceID': 'PLC.GG-gm1-00', 'timestamp': '2024-05-08 03:10:44.992000'}, {'variable': {'PLC_PRG.VarTimeCur1': {'val': Decimal('0'), 'type': 'Int64'}, 'GVL.MyVariable': {'val': Decimal('6789'), 'type': 'Int16'}, 'GVL.MyCount': {'val': Decimal('20001'), 'type': 'Int16'}, 'PLC_PRG.VarTimeCur0': {'val': Decimal('15920'), 'type': 'Int64'}, 'GVL.MyString': {'val': 'HELLO ICHIRI', 'type': 'String'}}, 'deviceID': 'PLC.GG-gm1-00', 'timestamp': '2024-05-08 03:16:44.042000'}, {'variable': {'PLC_PRG.VarTimeCur1': {'val':
:
:
:
'PLC_PRG.VarTimeCur0': {'val': Decimal('2420'), 'type': 'Int64'}, 'GVL.MyString': {'val': 'HELLO ICHIRI', 'type': 'String'}}, 'deviceID': 'PLC.GG-gm1-00', 'timestamp': '2024-05-10 02:20:27.783000'}], 'Count': 22, 'ScannedCount': 22, 'ResponseMetadata': {'RequestId': '1PTAEQEQ3AINM9GF474H5FBESBVV4KQNSO5AEMVJF66Q9ASUAAJG', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Fri, 23 Aug 2024 06:21:15 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '9655', 'connection': 'keep-alive', 'x-amzn-requestid': '1PTAEQEQ3AINM9GF474H5FBESBVV4KQNSO5AEMVJF66Q9ASUAAJG', 'x-amz-crc32': '3499982193'}, 'RetryAttempts': 0}}
コード記述
- s3のmybucket-tokyo-ichiri/myData/TestFromDynamoDB/にタイムスタンプの付いたファイル名でcsvを書込みます。
- s3にcsvファイル保存したいbucketとフォルダを作成しておき、下のコードを正しいbucket名とフォルダ名に置き換えます。
- エラーが無いか『Test』で実験します。
import json
import boto3
from boto3.dynamodb.conditions import Key
import os
import datetime
import csv
from io import StringIO
from decimal import Decimal
print('*******Loading MyFuncDynamo2s3')
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('gm1_table') # Table Name
iot = boto3.client('iot-data')
# Initializing S3 client
s3 = boto3.client('s3')
BUCKET_NAME = 'mybucket-tokyo-ichiri'
def flatten_data(data):
flattened_data = []
for entry in data:
# タイムスタンプをエポック時間に変換
timestamp = datetime.datetime.strptime(entry['timestamp'], '%Y-%m-%d %H:%M:%S.%f')
epoch_time = timestamp.timestamp()
flat_entry = {
'deviceID': entry['deviceID'],
'tiemstamp':entry['timestamp'],
'timestampEPOCH': epoch_time # エポック時間を使用
}
for key, value in entry['variable'].items():
if isinstance(value['val'], Decimal):
# Decimal型を浮動小数点数に変換
flat_entry[key] = float(value['val'])
else:
flat_entry[key] = value['val']
flattened_data.append(flat_entry)
return flattened_data
def lambda_handler(event, context):
global i
current_time = datetime.datetime.utcnow().strftime('%Y-%m-%dT%H-%M-%S')
s3_key = f'myData/TestFromDynamoDB/data_{current_time}.csv'
START_TIMESTAMP="2024-05-05 02:30:35.527212"
END_TIMESTAMP="2024-05-10 02:30:47.530207"
option = {
'KeyConditionExpression':
Key('deviceID').eq("PLC.GG-gm1-00") & \
Key('timestamp').between(START_TIMESTAMP, END_TIMESTAMP)
}
res = table.query(**option)
print(res)
flattened_data=flatten_data(res['Items'])
#raise Exception('Something went wrong')
# CSV形式に変換
csv_output = StringIO()
csv_writer = csv.DictWriter(csv_output, fieldnames=flattened_data[0].keys())
csv_writer.writeheader()
csv_writer.writerows(flattened_data)
# S3にCSVをアップロード
s3.put_object(Bucket=BUCKET_NAME, Key=s3_key, Body=csv_output.getvalue())
return {
'statusCode': 200,
'body': 'CSV file created and uploaded to S3!'
}
Testで以下の様になればOK。
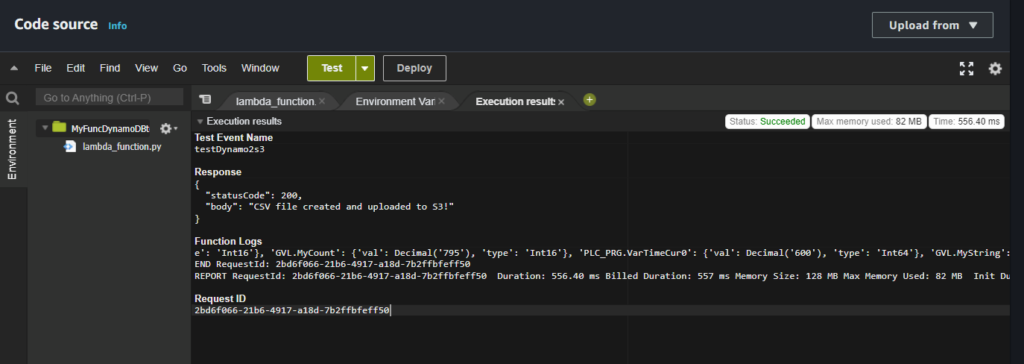
『Deploy』を押します。 これで実行可能です。
トリガ
- テスト用のトリガを設定します。
- 『Add trigger』
- Trigger configuration
- select a sourceのプルダウンで『AWS IoT』を選択
- 『Custom IoT rule』、「Create a new rule』に変更
- Rule nameに覚えやすい名前を入れる『MyLambdaTestTopic』
- Rule query statement 『SELECT * FROM ‘topic’』と入れる。これでMQTTテストでtopicというトピックで何でもpublishするとtriggerが発生しLambdaが実行される。
- 『Add』でtriggerの作成完了
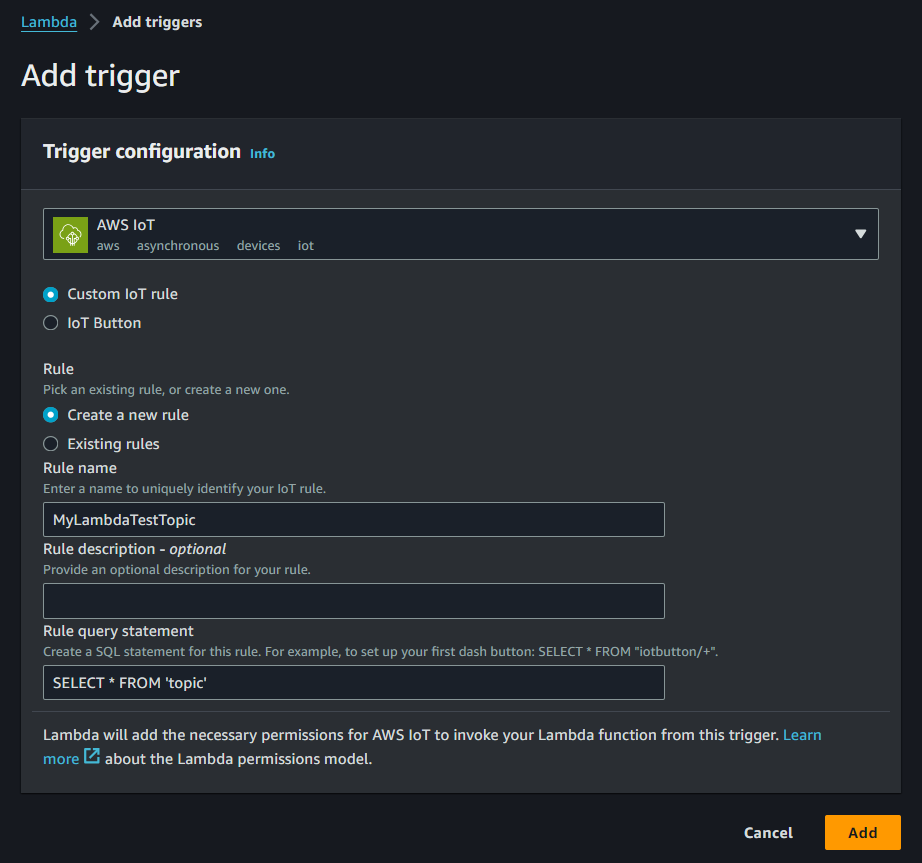
triggerが作成されました。
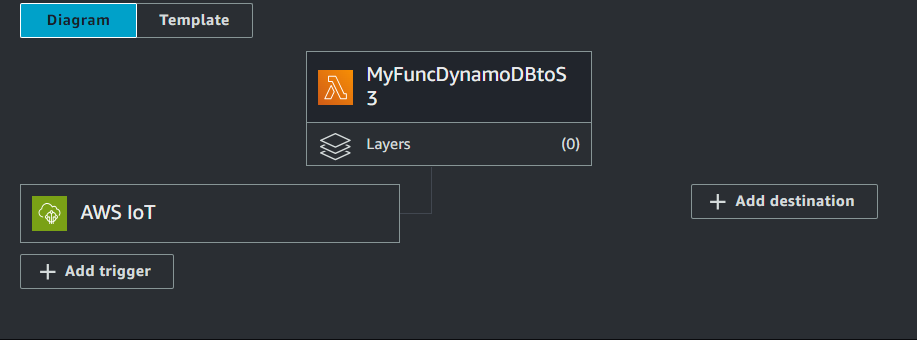
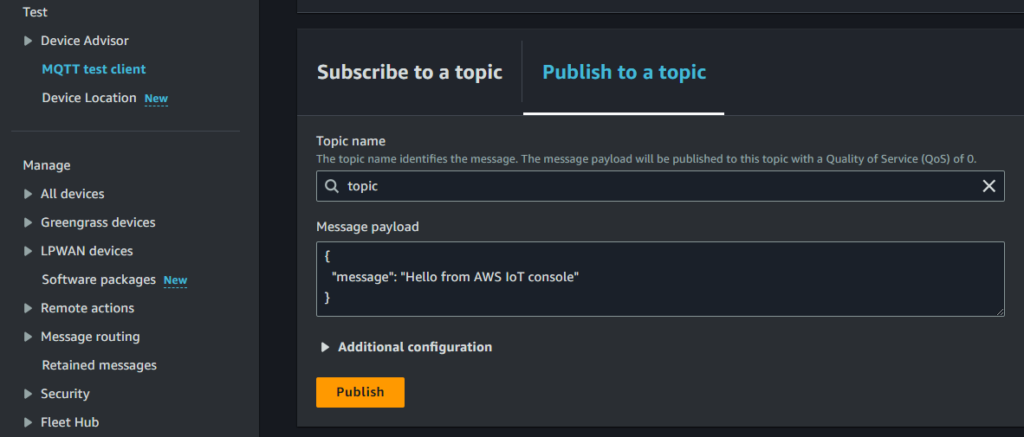
テスト
- AWS IoT MQTT test clientに行き
- Topic nameに先ほどSQL文で指定した『topic』と入れる
- Message payloadは変更せずに
- 『Publish』を押す
- すると、トピック名topicでMessageがPublishされました。
- これでLambdaのtriggerがトピック名がtopicのメッセージを受信したので、Lambda関数が実行されている筈です。
テストして、CloudWatchでログ確認してLambda関数を修正した時は、毎回Deployを押す事を忘れないように。
確認
- 予め作成しているcsvファイル格納用のs3のフォルダに移動します。
- 書込めていますね。
- csvの中身はチェックを入れて『Download』してローカルPCでチェックします。
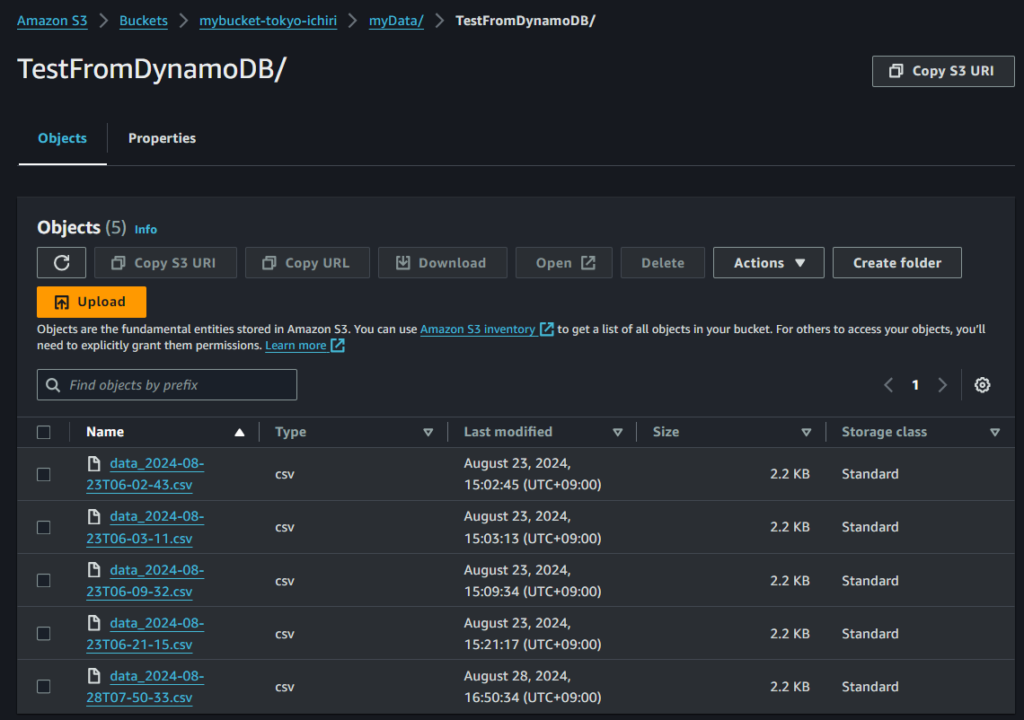
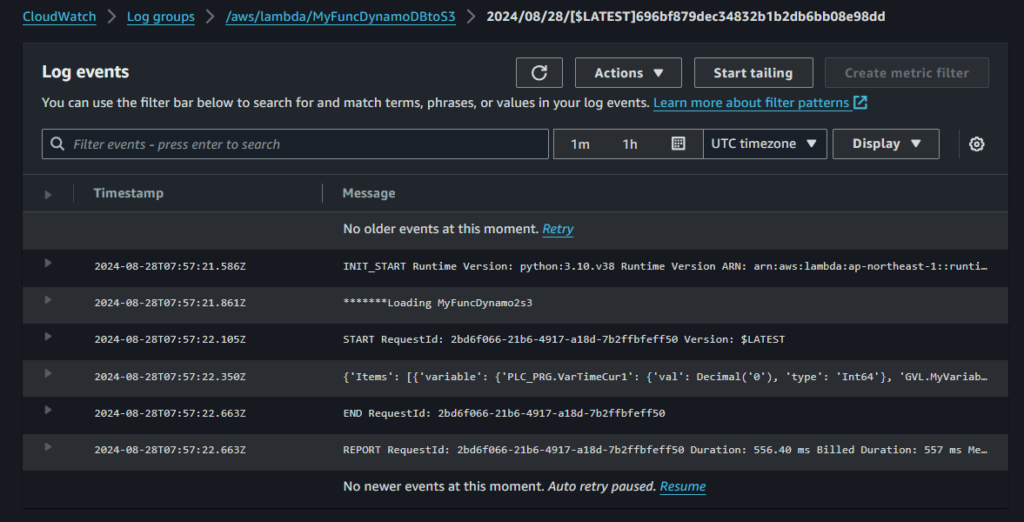
デバッグ
- CloudWatch画面にはいり左メニューから『Log groups』
- 作成したLambda関数名が付いた『/aws/lambda/MyFuncDynamoDBtoS3』をクリック
- Log streamの最新のものをクリックします
- 以下の様に入ってきています。
- 左の▶をクリックすると開いて内容を確認できます。
- エラーがあればここに表示されます。
- print文の内容もここに表示されます。

コメント